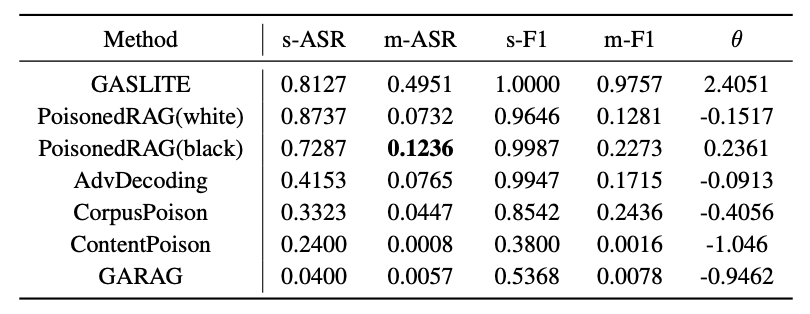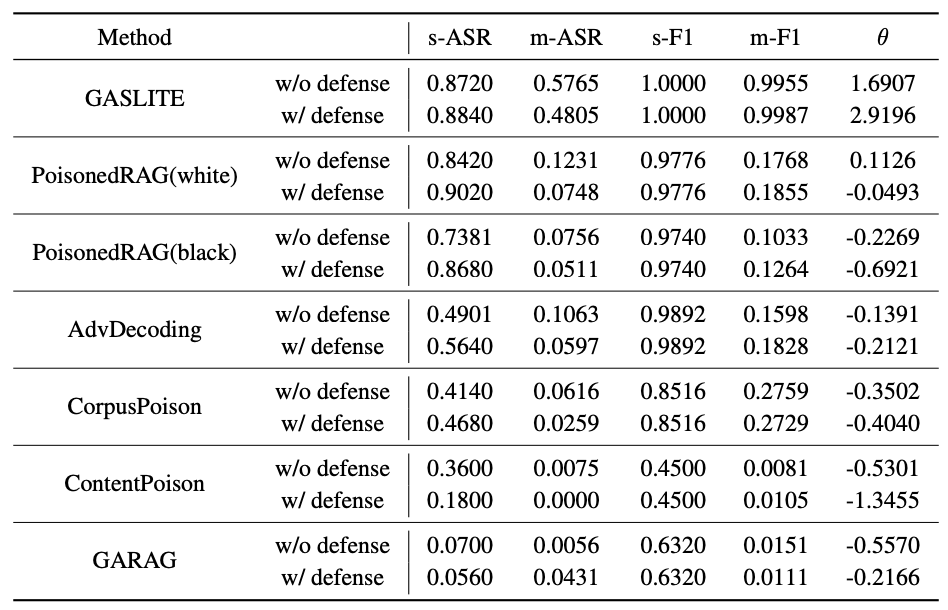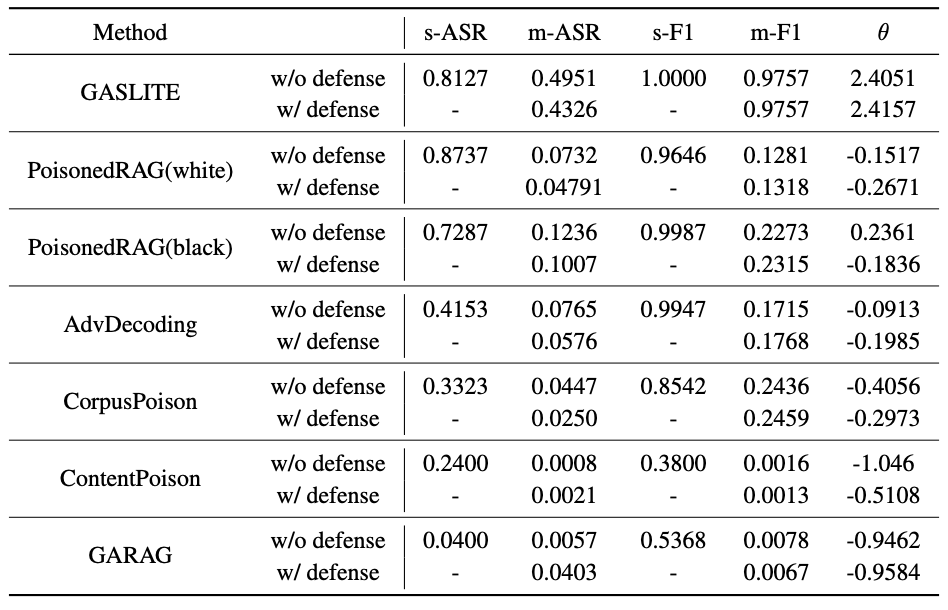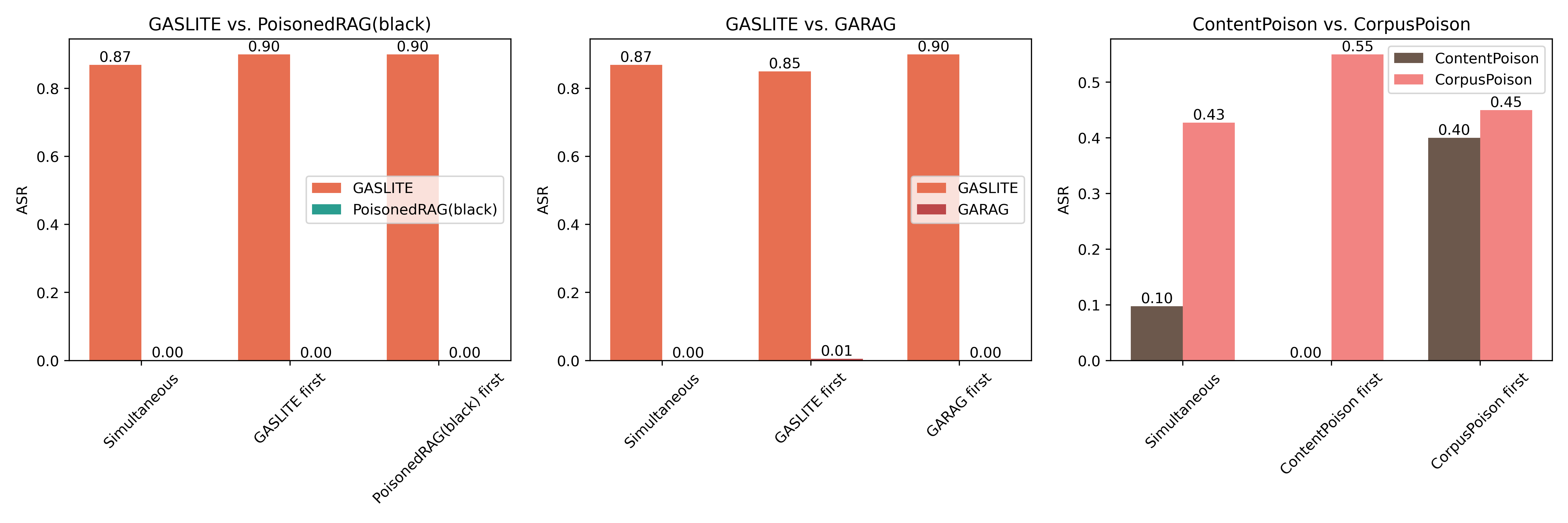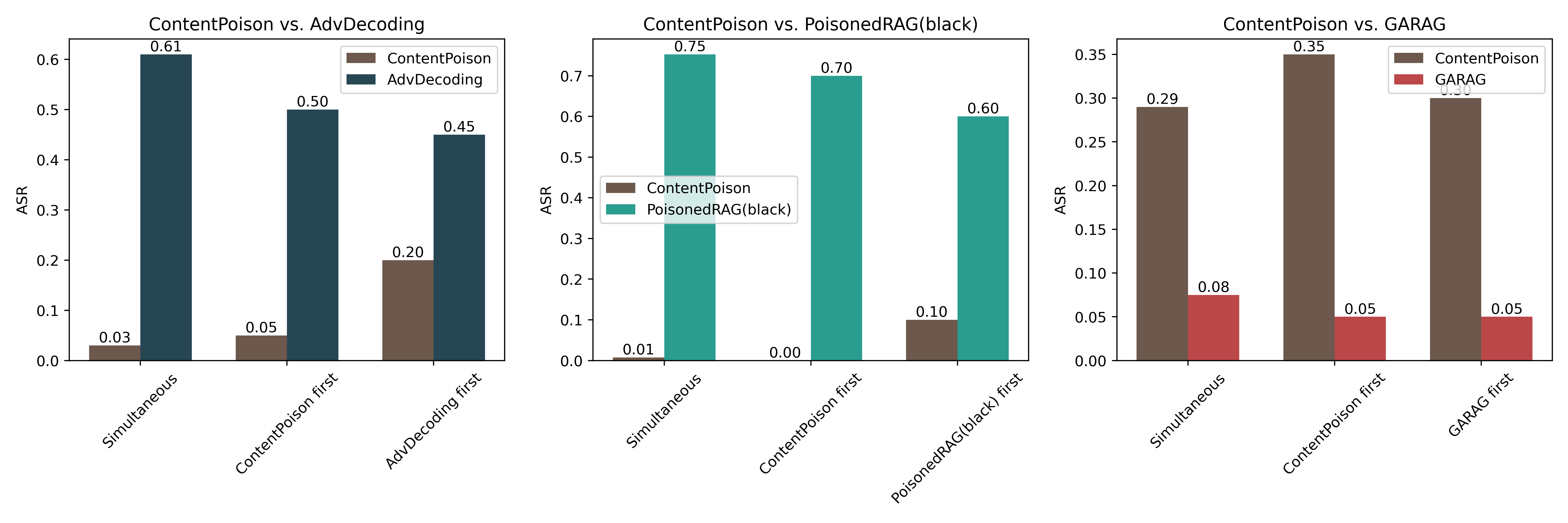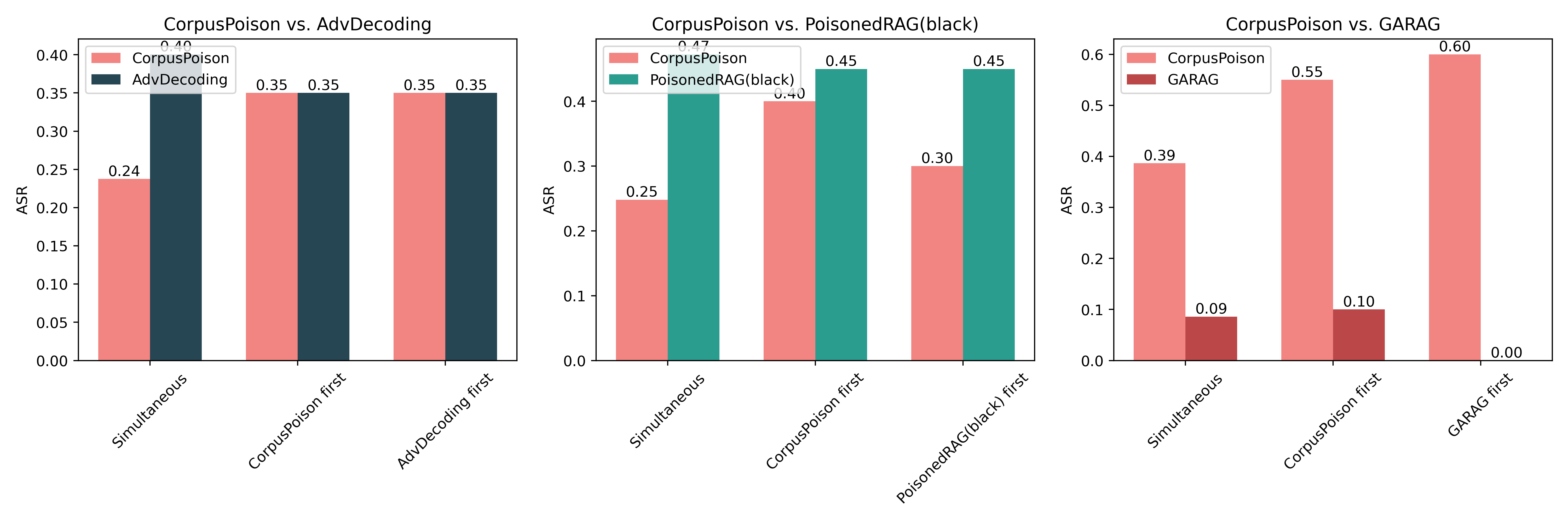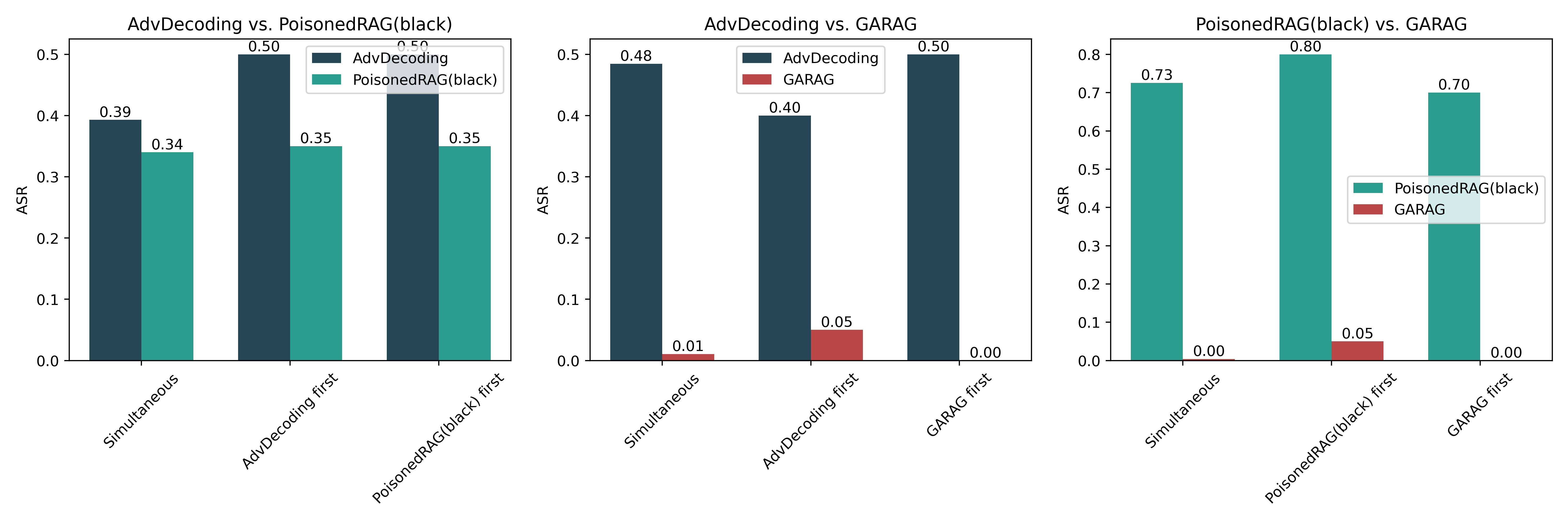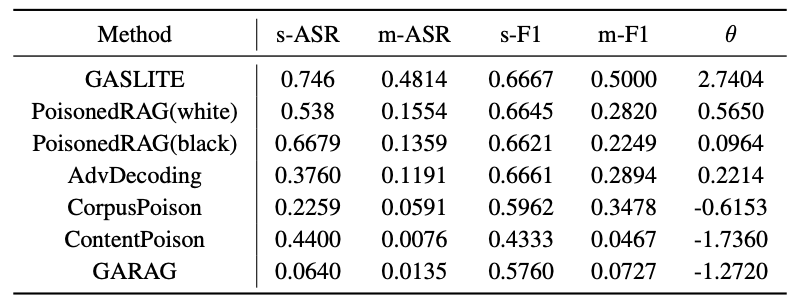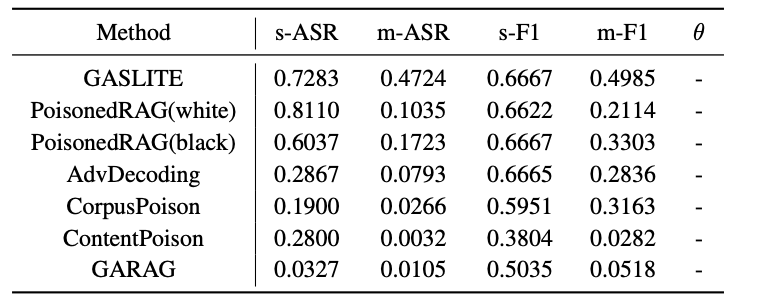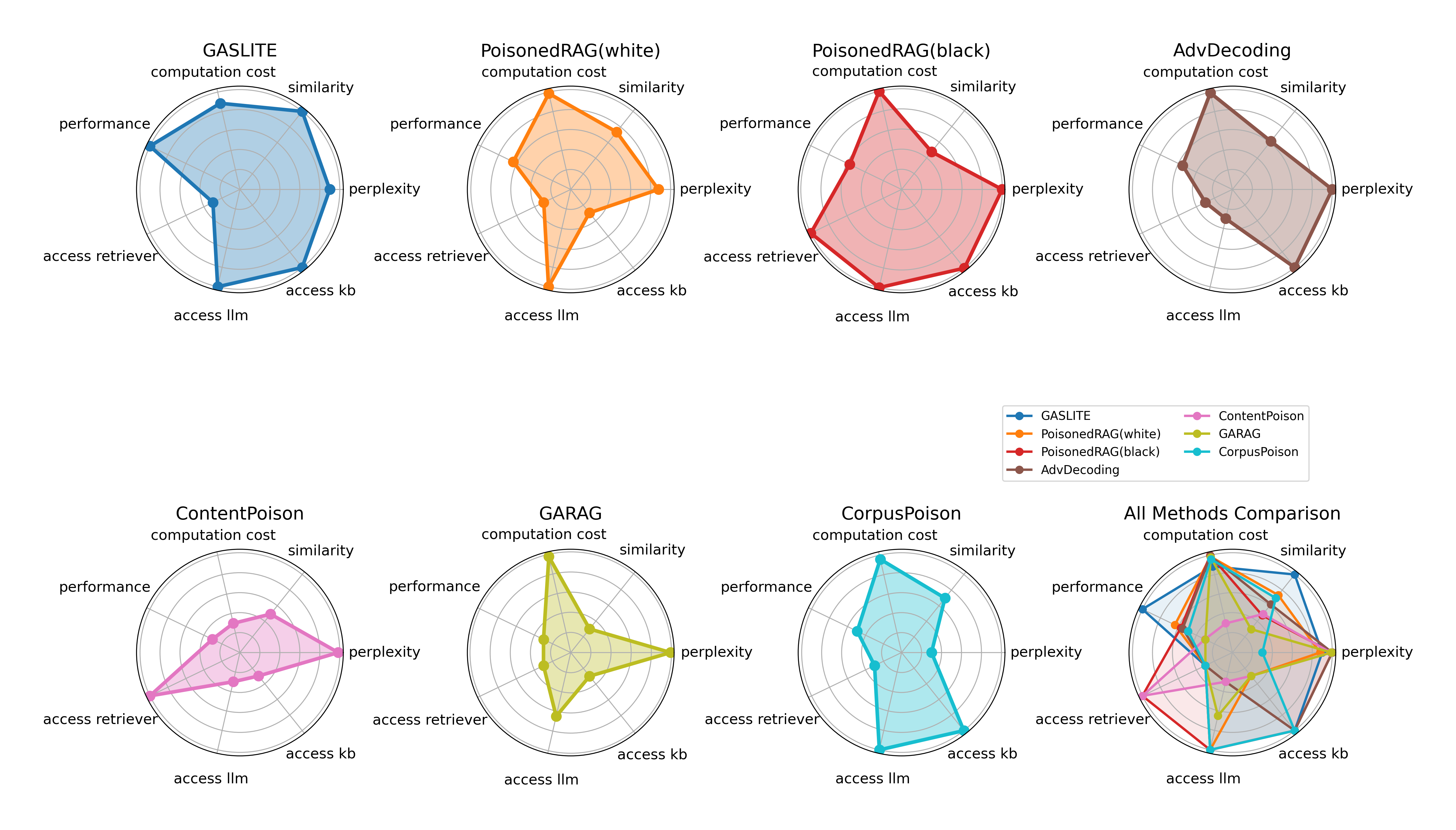
| # | Method | s-ASR | m-ASR | s-F1 | m-F1 | θ |
|---|---|---|---|---|---|---|
| GASLITE | 0.8720 | 0.5765 | 1.0000 | 0.9955 | 1.6907 | |
| PoisonedRAG(white) | 0.8420 | 0.1231 | 0.9776 | 0.1768 | 0.1176 | |
| PoisonedRAG(black) | 0.7381 | 0.0756 | 0.9740 | 0.1033 | -0.2269 | |
| AbvDecoding | 0.4901 | 0.1063 | 0.9892 | 0.1598 | -0.1391 | |
| CorpusPoison | 0.4140 | 0.0616 | 0.8516 | 0.2759 | -0.3502 | |
| ContentPoison | 0.3600 | 0.0075 | 0.4500 | 0.0081 | -0.5301 | |
| GARAG | 0.0700 | 0.0056 | 0.6320 | 0.0151 | -0.5570 |
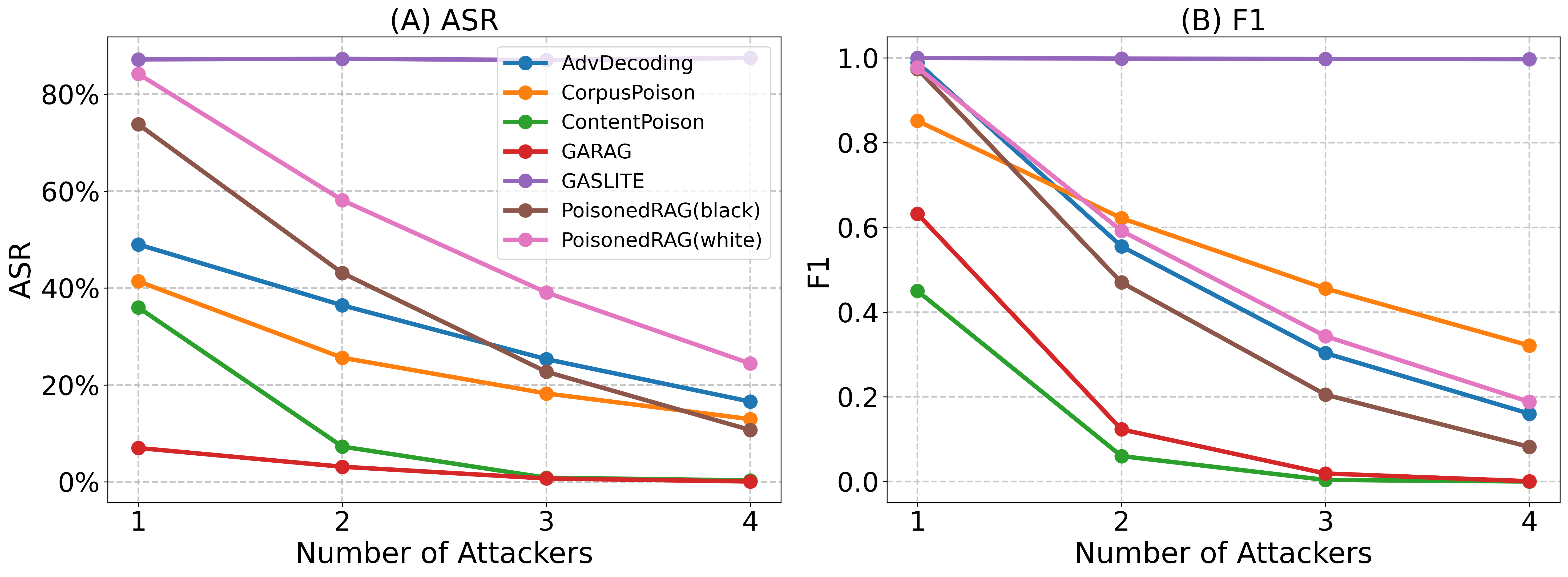
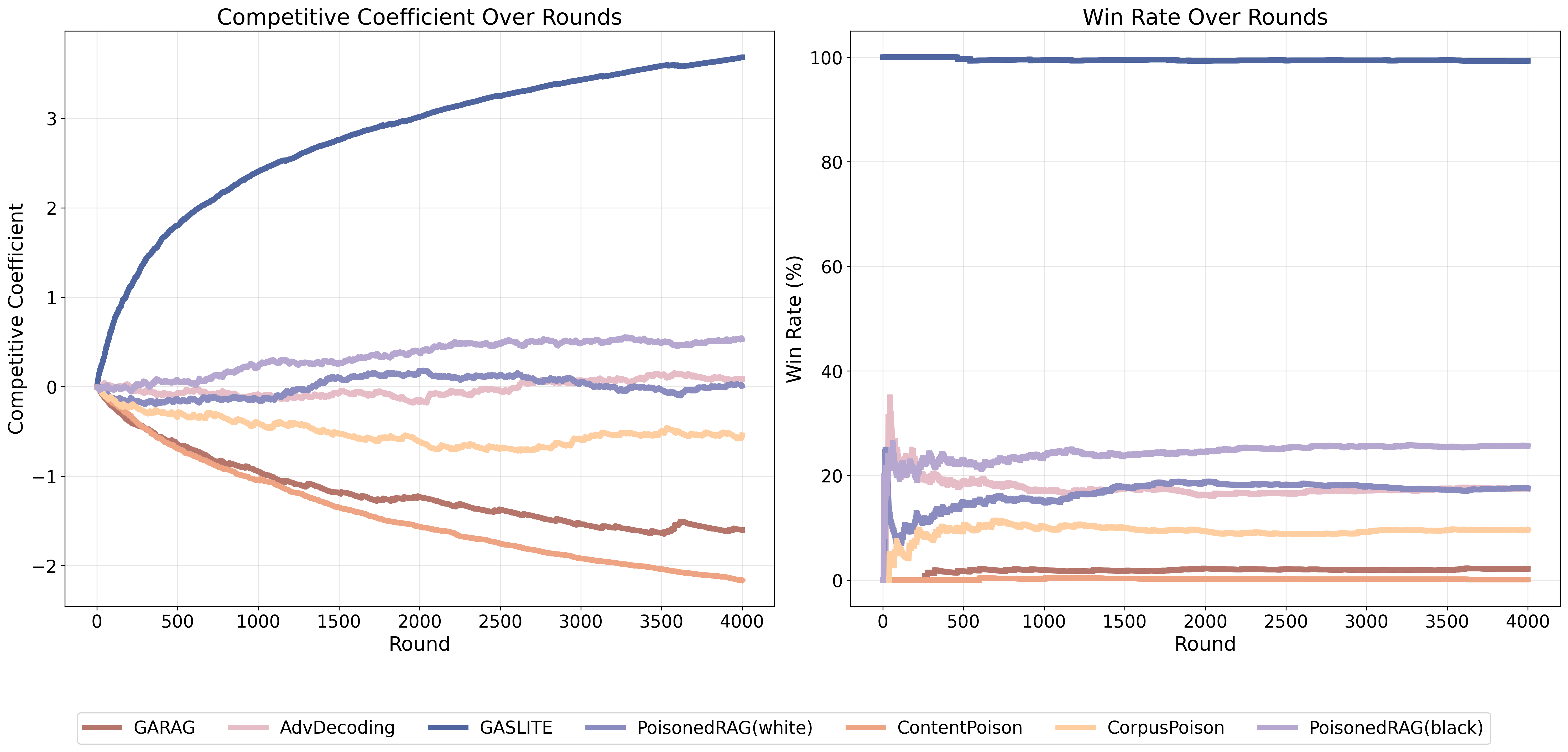
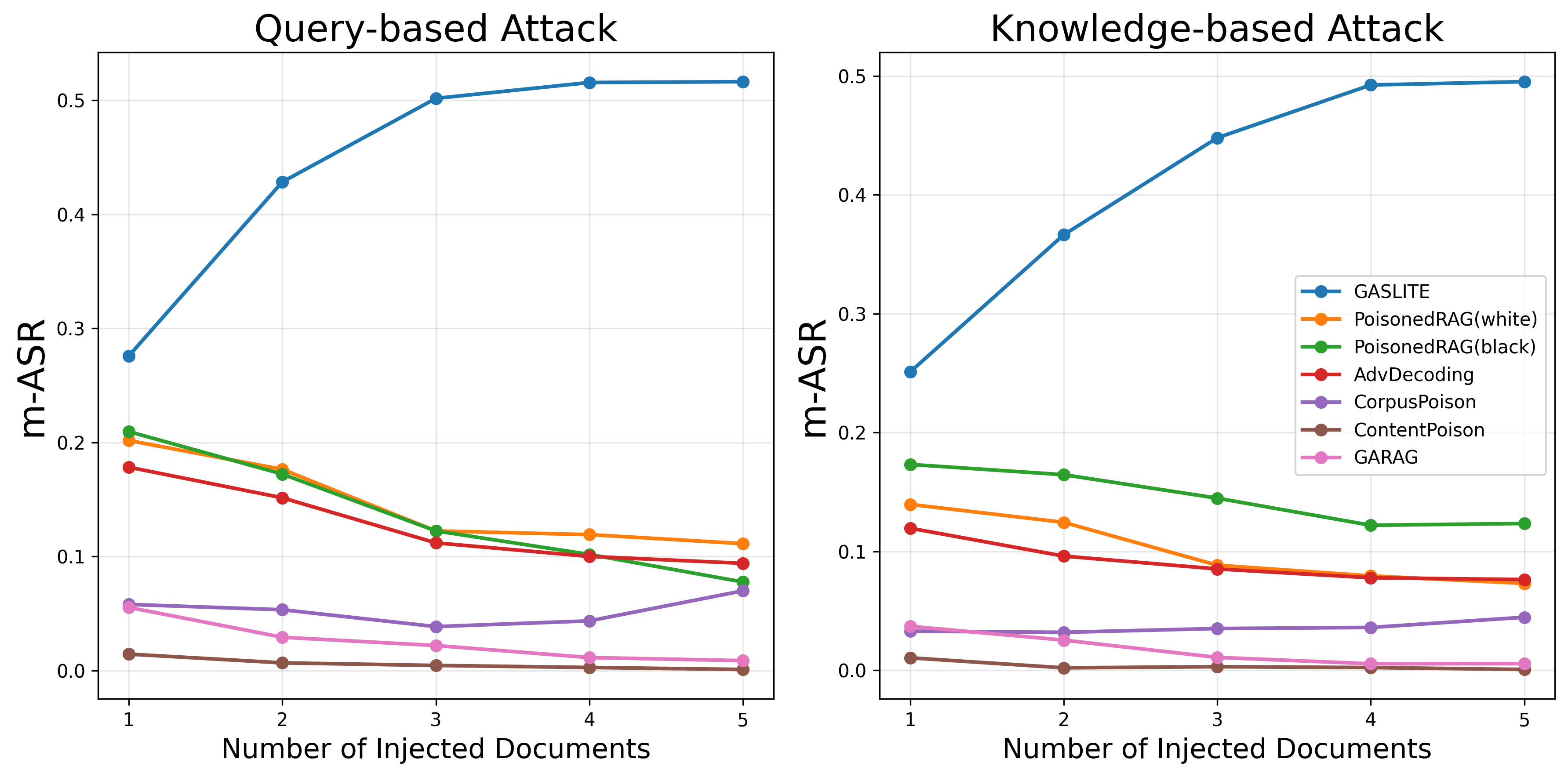
s-ASR: Attack Success Rate in Single-Attacker Scenario
m-ASR: Attack Success Rate in Multi-Attacker Scenario
s-F1: F1 Score in Single-Attacker Scenario
m-F1: F1 Score in Multi-Attacker Scenario
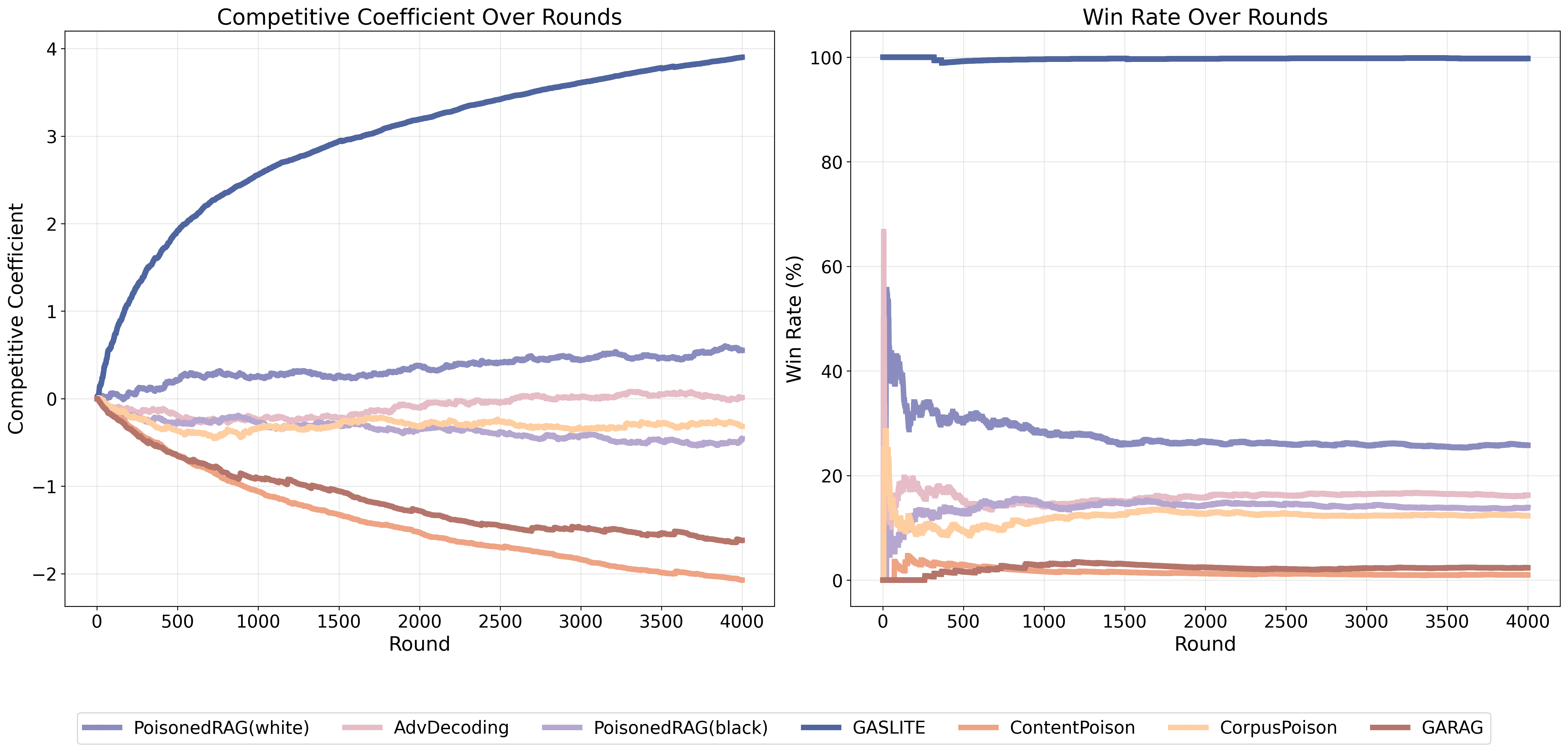
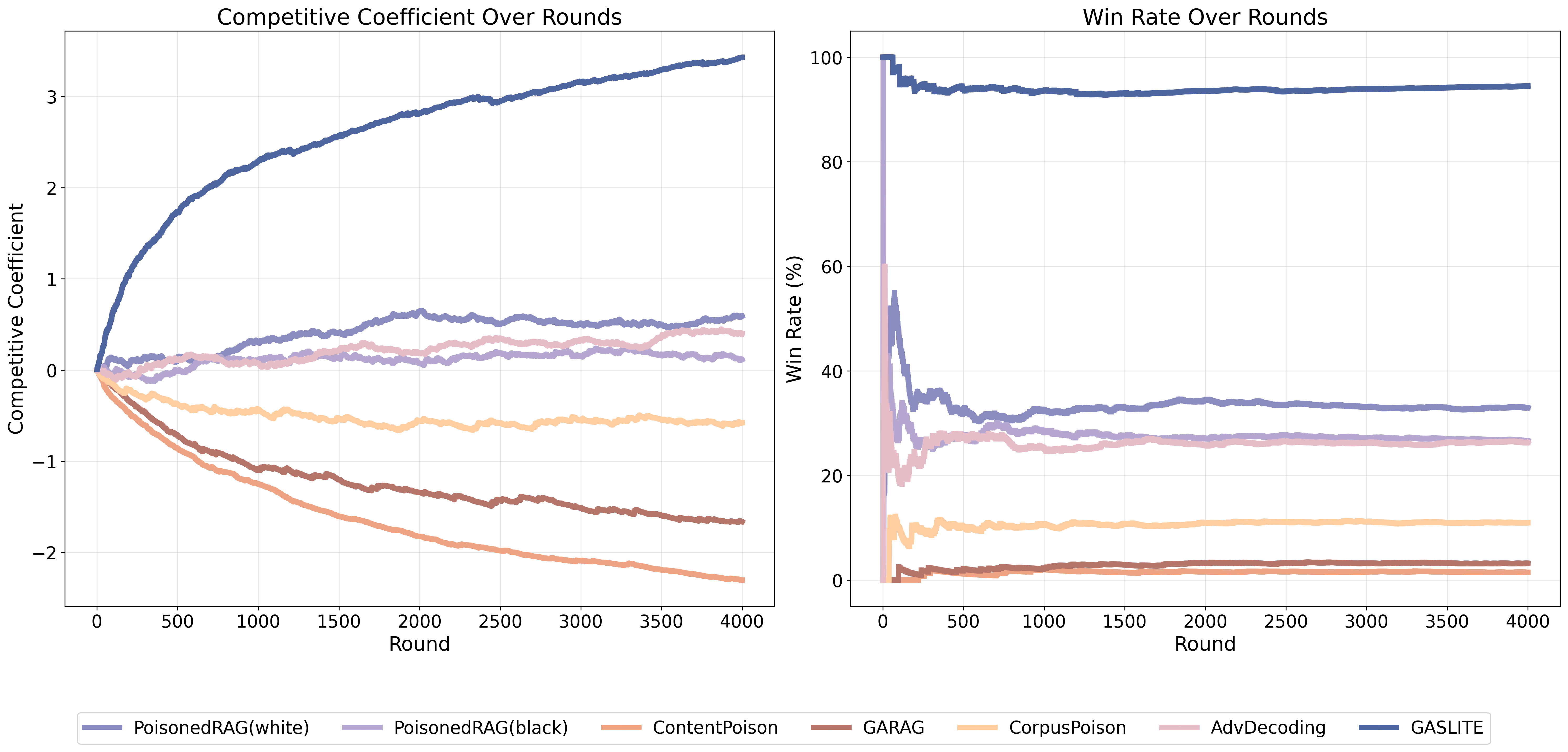
θ: Competitive Effectiveness